Training an RL Agent to Play Slay the Spire 2
A distributed PPO (Proximal Policy Optimization) agent that learns to play Slay the Spire 2 combat from scratch, using a custom C# game mod, TCP bridge, and Python training pipeline.
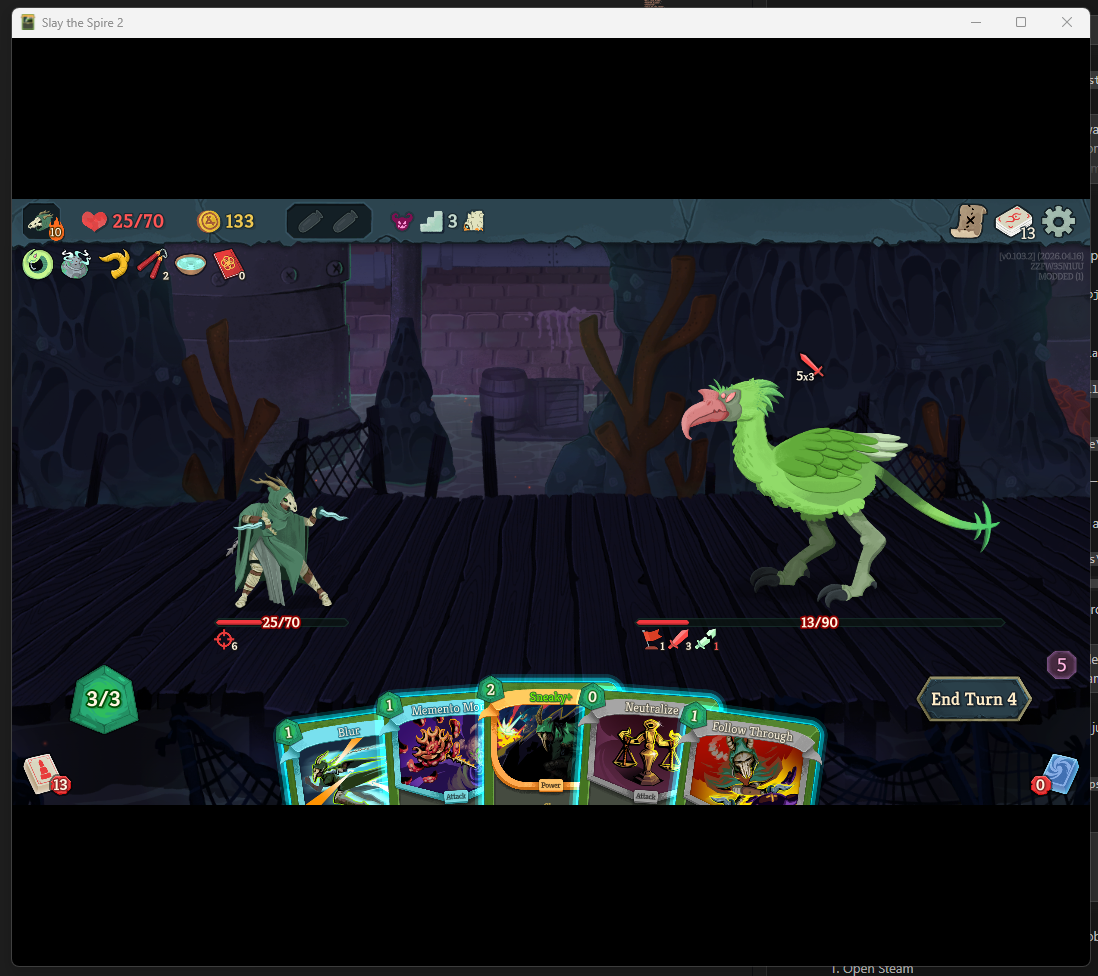
What is this?
Slay the Spire 2 is a roguelike deck-building game where you build a deck of cards and fight through a series of increasingly difficult enemies. This project trains a neural network to play the combat portion of the game using reinforcement learning (RL).
The agent sees the same information a human player does — cards in hand, enemy HP and intent, active buffs/debuffs, relics — and decides which card to play or whether to end its turn. It learns entirely through self-play, starting from random actions and gradually improving through PPO.
How it works
- C# Harmony mod hooks into the game, serializes combat state as JSON, and sends it over TCP.
- Python actor proxy receives states, runs inference with the policy network, and returns actions.
- Learner collects completed episodes from actors and trains the policy with PPO.
- Distributed workers run headless game instances across multiple machines over LAN.
- Curriculum stages the training from simple fights with starter decks to elite enemies with full card pools.
Architecture
The system runs across multiple machines. Each worker laptop runs several headless game instances connected to a local actor proxy. The actor proxies communicate with a central learner that collects rollouts and trains the shared policy.
Training Curriculum
Training follows a 13-stage curriculum that gradually increases difficulty.
Current Results
The agent is currently training on Stage 12 (the final stage) with the full Silent card pool against Act 1 elite enemies. Check the blog tabs for detailed write-ups on specific challenges and technical deep dives.